
A large language model (LLM) is a type of artificial intelligence (AI) program that can
recognize and generate text, among other tasks. LLMs are trained on huge sets of
data — hence the name “large.” LLMs are built on machine learning: specifically, a
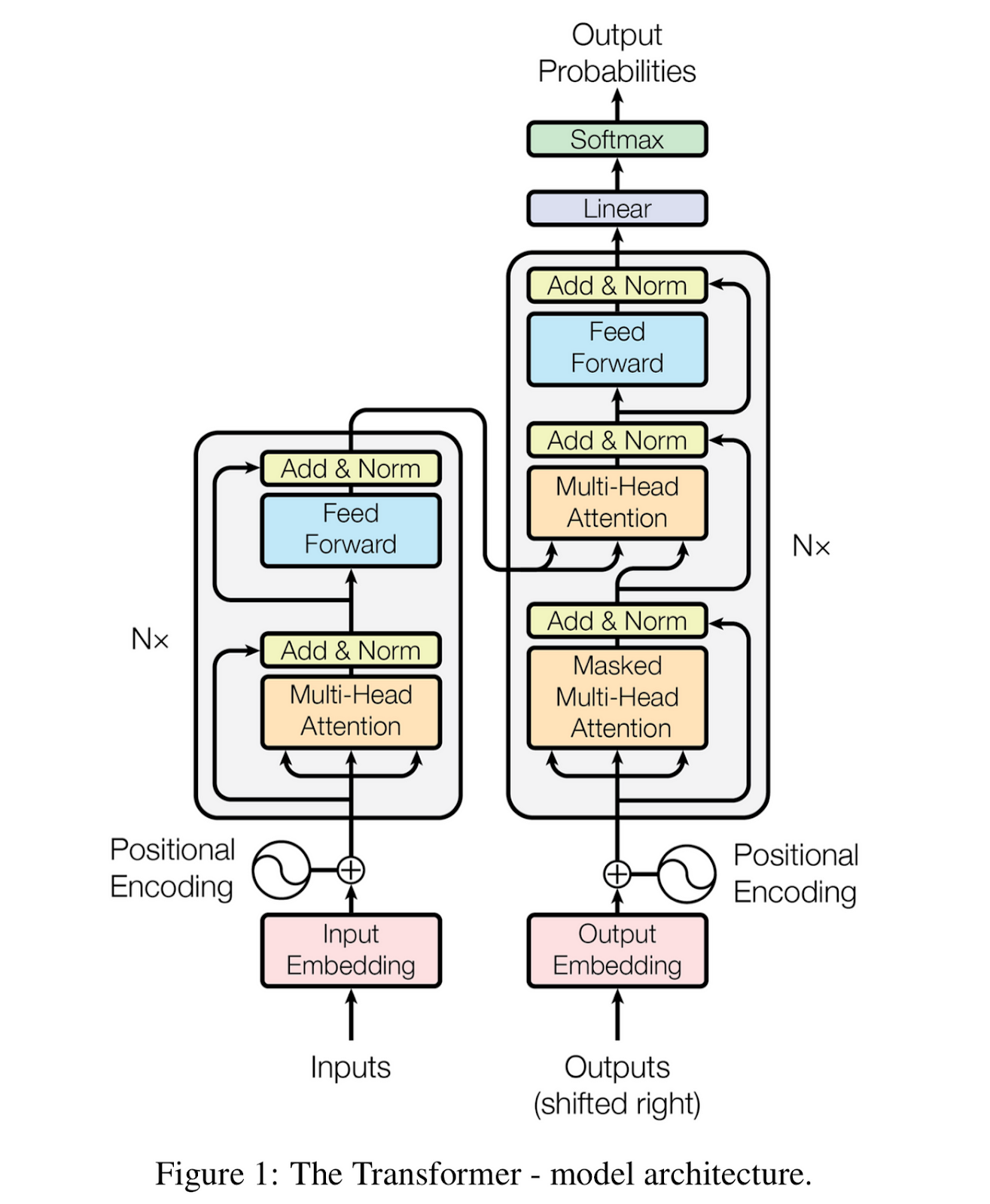
type of neural network called a transformer model.

In simpler terms, an LLM is a computer program that has been fed enough examples to be able to recognize and interpret human language or other types of complex data. Many LLMs are trained on data that has been gathered from the Internet — thousands or millions of gigabytes’ worth of text. But the quality of the samples impacts how well LLMs will learn natural language, so an LLM’s programmers may use a more curated data set.
LLMs use a type of machine learning called deep learning in order to understand how characters, words, and sentences function together. Deep learning involves the probabilistic analysis of unstructured data, which eventually enables the deep learning model to recognize distinctions between pieces of content without human intervention.
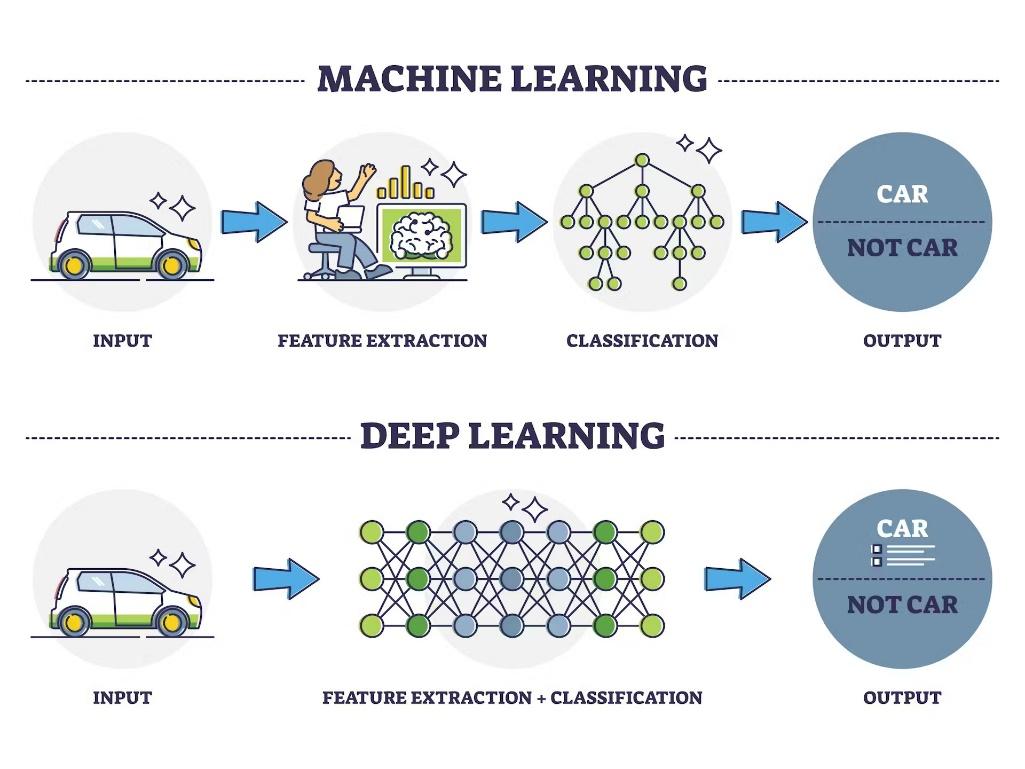
LLMs are then further trained via tuning: they are fine-tuned or prompt-tuned to the particular task that the programmer wants them to do, such as interpreting questions and generating responses, or translating text from one language to another.
LLMs have become a critical component of artificial intelligence research and development. These powerful models exhibit impressive capabilities in text generation, translation, question answering, and other natural language processing (NLP) tasks. To understand the vast LLM landscape, we can categorize them based on their architecture, training data, and resulting functionalities.
LLM Types:
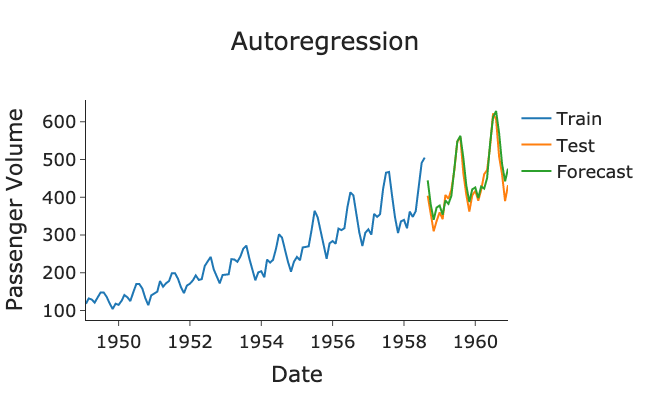
1. Autoregressive Models:
- Function: Generate text sequentially, one token (word or sub-word) at a time. They predict the most likely next token based on the preceding sequence.
- Strengths: Well-suited for open-ended text generation tasks like creative writing or code production.
- Examples: GPT-3 (OpenAI), Jurassic-1 Jumbo (AI21 Labs), Megatron-Turing NLG (NVIDIA)
2. Conditional Generative Models:
- Function: Generate text tailored to a specific input, such as a prompt, topic, or style. This allows for more control over the generated output compared to autoregressive models.
- Strengths: Ideal for tasks requiring specific content direction, like summarizing a factual topic or writing different creative content formats (poems, scripts, etc.).
Examples:GEMINI (Meta AI), T5 (Google AI), Jurassic-1 GPT (AI21 Labs)

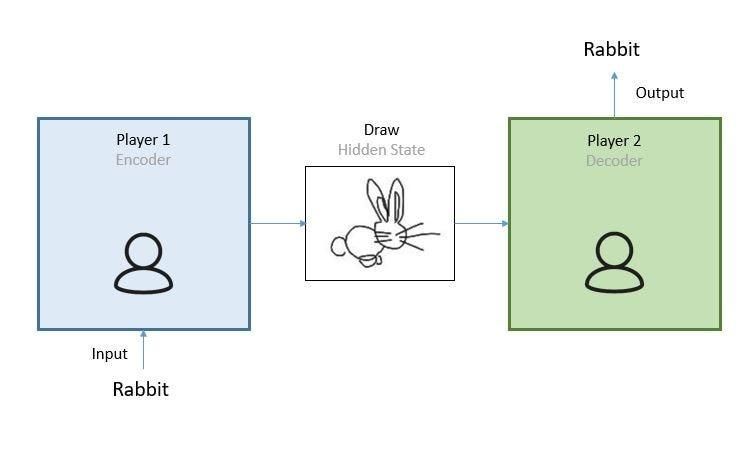
3. Encoder-Decoder Models:
- Function: These models employ a two-stage process. First, they encode the input text, capturing its meaning and relationships. Then, they decode the encoded representation into a new format, such as a summary or a translation in a different language.
- Strengths: Excel at tasks requiring understanding the context of the input text, like generating summaries or performing machine translation.
- Examples: BERT (Google AI), XLNet (Google AI & Carnegie Mellon University), BART (Meta AI)
4. Masked Language Models (MLMs):
- Function: Trained to predict a masked word within a sentence. This process helps them learn the relationships between words and their context, improving their understanding of language structure.
- Strengths: Contribute to the overall performance of various other LLMs, particularly those using the Transformer architecture (explained below).
- Examples: BERT (Google AI), RoBERTa (Facebook AI)
5. Transformer-based Models:
- Function: A significant portion of contemporary LLMs leverage the Transformer architecture, a deep learning technique designed for sequence-to-sequence tasks. Transformers excel at tasks like language translation and text generation by analyzing the relationships between words and their positions within a sequence.
- Examples: Most of the previously mentioned models (GPT-3, BART, T5, etc.) fall under this category.
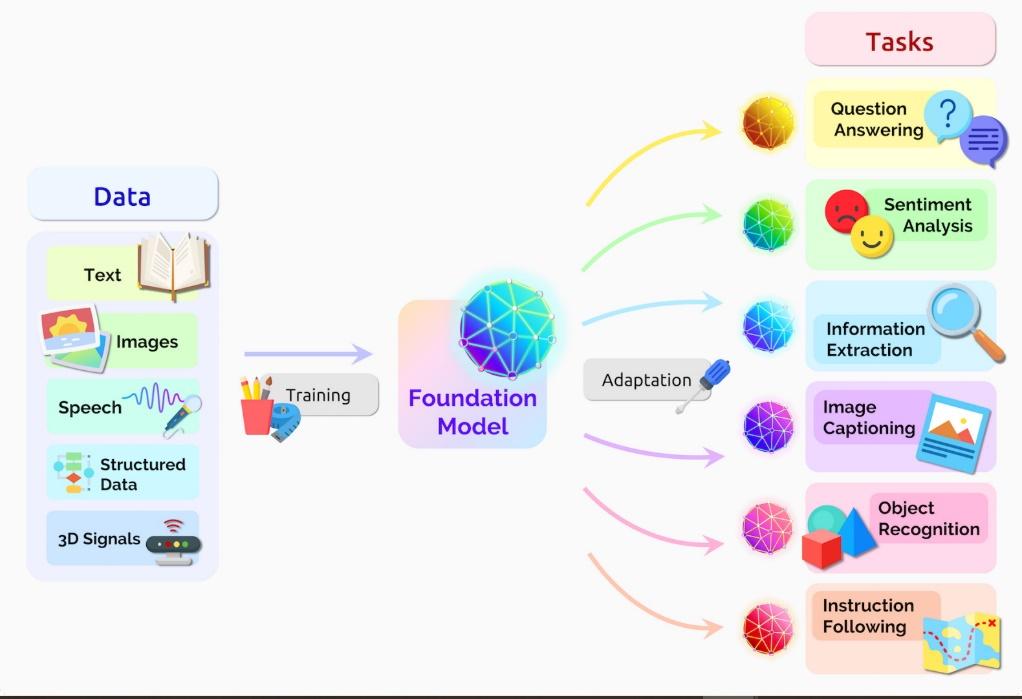
Selecting the Right LLM:
The optimal LLM for your project hinges on your specific needs. Consider factors like the desired type of text generation or analysis, the availability of training data, and any limitations in computational resources. By understanding the different LLM types and their strengths, you can make informed decisions to leverage these powerful tools effectively in your NLP endeavors.