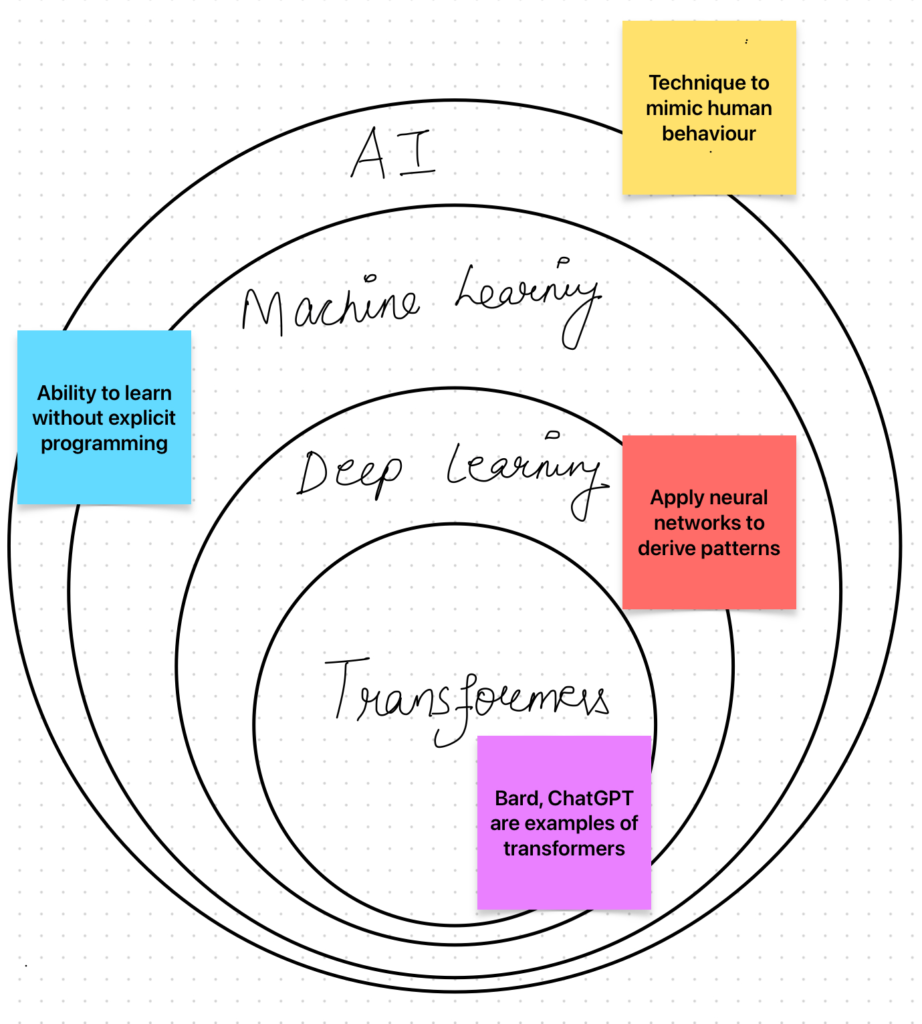
Blog
AI Transformer

Unraveling the Mysteries of AI Transformers: The Past, Present, and Future
In the realm of artificial intelligence (AI) and machine learning (ML), the evolution of models and algorithms is a continuous journey towards efficiency, accuracy, and versatility. Among these innovations, the Transformer model stands out as a groundbreaking development that has reshaped the landscape of natural language processing (NLP) and beyond. This blog post dives into the intricacies of the Transformer model, tracing its evolution, understanding its advantages and disadvantages, and speculating on its future scope.
The Genesis of Transformers
The story of Transformers begins in 2017, when Vaswani et al. introduced the world to the Transformer model in their seminal paper, “Attention is All You Need.” Before this, recurrent neural networks (RNNs) and their more advanced variants like long short-term memory (LSTM) networks were the go-to architectures for processing sequential data, especially in NLP tasks. However, these models had significant drawbacks, including difficulties with long-term dependencies and computational inefficiency due to their sequential nature.
The Transformer model revolutionized this approach by relying entirely on attention mechanisms, eliminating the need for recurrence. This model could process all elements of the input data in parallel, significantly improving efficiency and performance on tasks requiring an understanding of long-range dependencies in text.
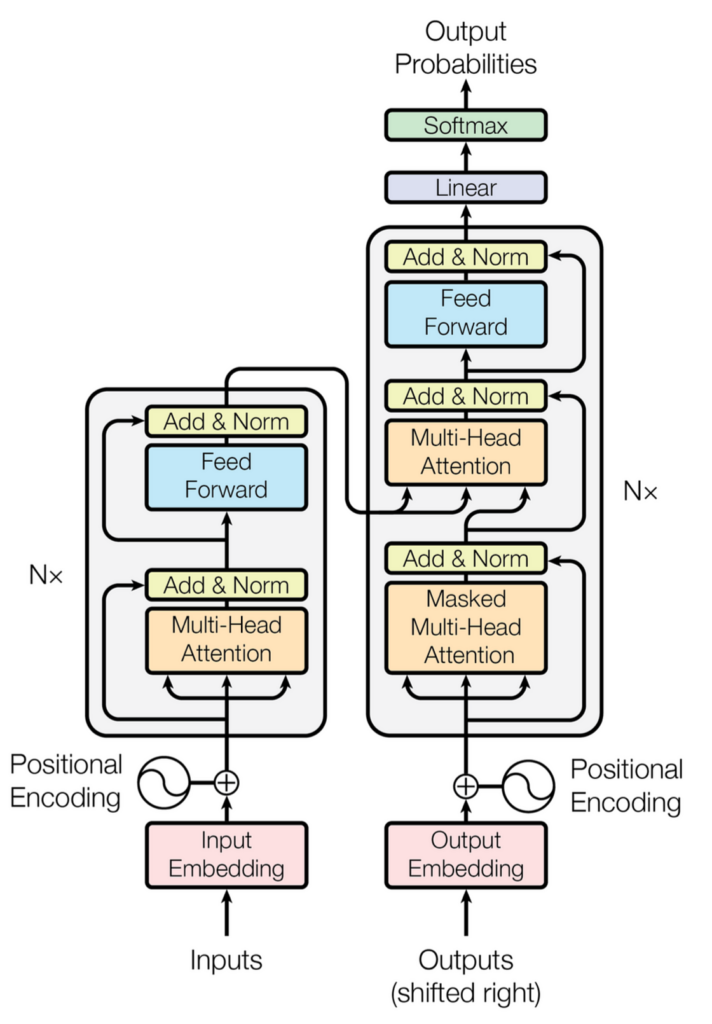
How Transformers Work
At the core of the Transformer architecture is the self-attention mechanism, which allows the model to weigh the importance of different parts of the input data differently. This is crucial for understanding the context and nuances of language. The Transformer processes input data through an encoder-decoder structure, with each consisting of multiple layers of attention and feed-forward neural networks. This design enables the model to capture complex relationships in the data, making it incredibly powerful for a wide range of applications.
Evolution and Variants
Since its inception, the Transformer model has spawned numerous variants, each aiming to improve upon the original in various ways. Some notable examples include:
BERT (Bidirectional Encoder Representations from Transformers): Introduced by Google, BERT revolutionized how we approach tasks like question answering and language inference by pre-training on a large corpus of text and then fine-tuning for specific tasks.
GPT (Generative Pretrained Transformer): OpenAI’s series of models, including GPT-3, demonstrated remarkable abilities in generating human-like text, opening up new possibilities for AI in content creation, conversation, and more.
T5 (Text-to-Text Transfer Transformer): Google’s T5 reframed all NLP tasks into a unified text-to-text format, simplifying the process of applying transformers to a wide range of tasks.
Advantages of Transformers
Transformers offer several significant advantages over their predecessors:
Parallelization: Unlike RNNs and LSTMs, Transformers process all parts of the input data simultaneously, leading to much faster training times.
Handling Long-range Dependencies: The self-attention mechanism allows Transformers to better understand the context and relationships in the input data, regardless of distance between elements.
Flexibility and Adaptability: Transformers have been successfully applied to a broad spectrum of tasks beyond NLP, including computer vision, audio processing, and even protein structure prediction.
Disadvantages and Challenges
Despite their advantages, Transformers are not without their challenges:
Computational Cost: Training large Transformer models requires significant computational resources, making it inaccessible for some users and applications.
Data Hunger: To achieve their best performance, Transformers often need vast amounts of training data, which can be a limitation for niche applications.
Interpretability: Understanding the decisions and outputs of large Transformer models can be challenging, raising concerns about transparency and trustworthiness.
Future Scope and Potential
The future of Transformers is incredibly promising, with ongoing research focusing on addressing their current limitations and expanding their applications. Some areas of interest include:
Efficiency Improvements: Efforts like pruning, quantization, and the development of more efficient attention mechanisms aim to reduce the computational cost of training and deploying Transformer models.
Transfer Learning and Few-shot Learning: Advances in these areas could reduce the data requirements for training Transformers, making them more accessible and versatile.
Cross-domain Applications: Researchers are exploring the use of Transformers in areas beyond NLP, such as drug discovery, climate modeling, and more, where their ability to model complex relationships can drive significant advance.

Conclusion
In sum, the journey of Transformer models from their inception to their current state underscores a monumental shift in how we approach complex problems across various domains. These models have not only revolutionized natural language processing but also opened doors to their application in fields that were once considered beyond the reach of traditional machine learning techniques. As we stand on the brink of what might be the next great leap in AI, it’s clear that Transformers will play a pivotal role in shaping the future of technology.
However, the path forward is not without its challenges. The computational and data demands of these models, along with concerns regarding their interpretability and ethical use, are significant hurdles that the research community continues to tackle. Addressing these issues is crucial for ensuring that the benefits of Transformer technology can be fully realized and accessible to all, without exacerbating existing inequalities or introducing new risks.
As we look to the future, the potential of Transformer models is boundless. With ongoing advancements aimed at making these models more efficient, adaptable, and understandable, we are likely to see even more innovative applications emerge. From enhancing human creativity to solving some of the world’s most pressing problems, the transformative power of Transformers is only beginning to be tapped.
The evolution of Transformer models is a testament to the ingenuity and perseverance of the AI research community. It serves as a reminder of the incredible potential that lies in the intersection of curiosity, technology, and collaboration. As we continue to explore this potential, the story of Transformers is far from over; it is, in many ways, just getting started. The future beckons with promises of AI systems that are more integrated into our daily lives, driving forward not just technological innovation but also societal progress. In this journey, the Transformer stands as both a milestone and a beacon, guiding us towards a future where the language of machines and humans becomes ever more intertwined and mutually enriching.